
13.2.1 Incorrect identification of authors
Several academics have been critical of Google Scholar's data quality and parsing. In particular, Péter Jacsó discusses a number of Google Scholar failures in great detail in his paper in Online Information Review (Jacsó, 2005, 2006a/b). Whereas no doubt some of his critique is completely justified, I was unable to reproduce most of the specific Google Scholar failures detailed in his paper. This suggests that they either resulted from incorrect searches or that Google Scholar has rectified these failures.
Most importantly, the bulk of Jacsó's critique is leveled at inconsistent results for keyword searches, which are not relevant for the author and journal impact searches conducted with Publish or Perish. In addition, the summary metrics in Publish or Perish (e.g. h-index, g-index) are fairly robust and insensitive to occasional errors. I will discuss the problems he has identified with the identification of authors in some detail below.
Phantom Author I Introduction has disappeared
Jacsó signals some potentially important problems with the identification of authors, where parts of the text are identified as authors by Google Scholar. He claims (Jacsó, 2006b:299) that GS lists 40,100 documents where the author is I Introduction.
My own search in 2007 only found 956. However, 80% of these papers were not cited at all, whilst the average number of cites per paper for the remainder was 4.69. In many cases the actual author was listed in addition to the false I Introduction author. Only about 160 documents had both an incorrect I Introduction as only author and more than zero cites, and only 9 of those had more than 10 citations.
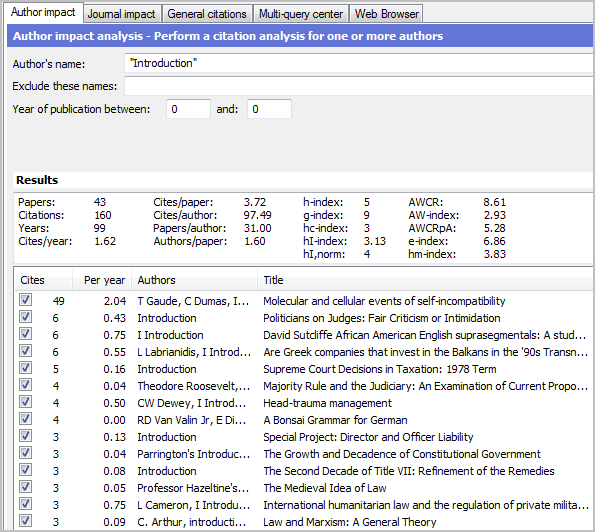
When I conducted a broader search (Introduction instead of I Introduction) in July 2010, I found only 43 documents that had Introduction as one of the authors and more than zero citations (see screenshot above). Only one document had more than 10 citations, and only 18 had more than 2 citations. There were only 14 documents with Introduction as their only author and they had an average of 2.79 citations. Hence, the problem is probably not nearly as big as one would initially believe, and it is certainly not a big issue for citation analysis.
Menu items as phantom authors
In a later paper Jacsó (2009) reports problems with menu items such as “Password”, “V Cart” featuring as authors. In July 2010, I was unable to find any authors with these names. When I tried “Username”, I did find some rubbish results, but there were only twelve hits (see below) and none of these will have any impact on author or journal impact queries.
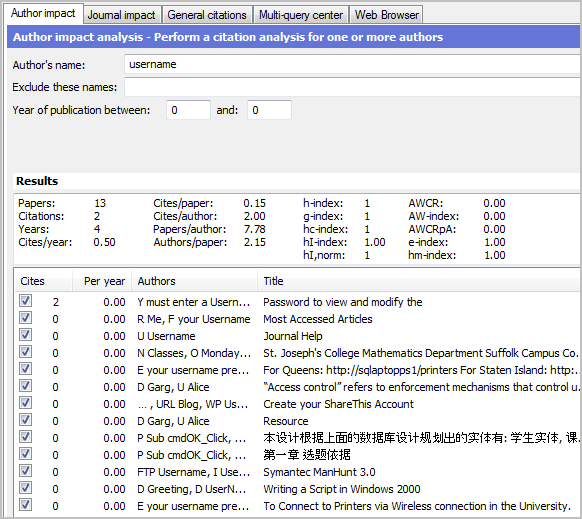
There does seem to be a serious problem, however, with articles published in The Lancet. When I searched for other likely menu items such as registered, login, options and access, I found a large number of papers in the Lancet where author names had been replaced entirely with menu options. Given that some of them had a very large number of citations, this might rob some legitimate authors of their publications.
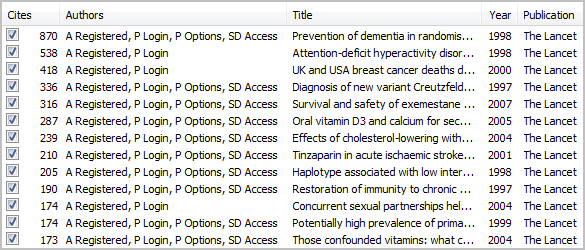
There are, however, only 359 papers with more than 10 citations and the problem seems to be limited to articles that are parsed from thelancet.com website. Publications parsed from other sources, such as Elsevier do not show the same problem. The Lancet publishes 300-400 articles a year, so although the 359 present a large number of papers, it by no means is a problem for the entire set of Lancet publications.
When limiting the search for the Lancet to publications after 1996 (when the problem seems to be more prominent), I find only 31 of the 1,000 most cited publications carrying inappropriate author names and they make up only 1.2% of the combined citations. So even for a fairly egregious Google Scholar parsing error, the actual impact on author or journal impact searches would be limited, especially when using robust measures such as the h-index.