
12.1.2 what metrics to use?
Obviously, your choice of metrics is also largely dependent on your research question. If you for instance want to study co-authorship patterns across countries or disciplines, the authors per paper would probably be the most appropriate metric. However, as indicated above most bibliometric studies on authors aim to measure research output and/or impact of a group of academics.
In that case, the choice of metrics is to some extent dependent on your personal preferences. Many of the metrics provided by Publish or Perish are highly correlated. This is natural as they are all based to some extent on the number of citations and papers. Therefore some bibliometric researchers decide to simply focus on these raw measures.
Number of papers or citations
Unfortunately, Google Scholar data are not flawless (see Chapters 13, 14 and 15 for a more extensive discussion of different data sources) and using the exact number of papers and citations might suggest a level of accuracy that is not present in the source data. I would certainly caution against using the number of papers or any measure derived from that (e.g. cites/paper) as a measure of research impact unless you are prepared to manually merge all stray references into their master records. This can be quite a tedious process.
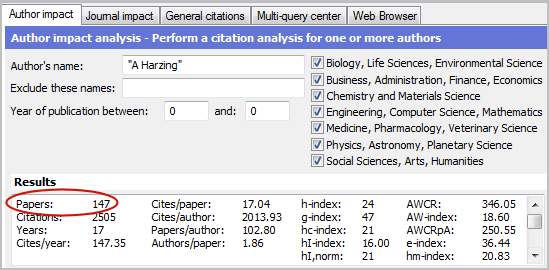
The screenshot above shows my “raw” citation record without any data cleaning and lists no less than 147 papers. The screenshot below shows my “cleaned” citation record after merging all stray references into their master records. The number of papers was reduced by 50% and as a result the number of cites per paper doubled.

Fortunately, not all scholars will show such a large difference between their “raw” citation record and cleaned citation records. In my case, a large number of stray citations are found, because I have a fairly large number of “non-traditional” publications, such as white papers (e.g. Reflections on the h-index), software (Publish or Perish) and book chapters, that are not always consistently referenced. The problem will generally be smaller for academics who only publish in journals.
The number of citations is not subject to stray citations. However, as indicated above, the number of citations in Google Scholar is not always entirely accurate and there might be some level of double-counting or non-academic citations (see also Chapter 13). This proportion is smaller than some Google Scholar critics seem to believe, but even so I would not recommend placing too much emphasis on the exact number of citations.
Another reason for this is that citations are subject to frequent change. For academics with a substantial publication record, citations will increase with every Google Scholar update. My own citation record has changed dozens of times during the months I wrote this book (hence the slightly different results in the different screenshots). This means that if your data collection period runs over several months, you will be disadvantaging academics whose citation scores are collected at the start of the project.
h-index or g-index
Because of the inherent inaccuracy and instability of citation and paper counts it might be better to focus on some of the more robust measures, such as the h-index and the g-index. These measures are not as vulnerable to small changes or inaccuracies in the source data. Incidental citations do not normally increase the h-index or g-index very much in relative terms unless the academic in question has a very low h-index or g-index (e.g. the difference between an h-index of 2 or 3).
However, the h-index and g-index can often increase by one or two points by merging stray references, especially if one of the academics publications is close to becoming part of the h-index. In my case, both the h-index increased by one and the g-index increased by 2 through carefully merging all stray citations, which is an increase of less than 5%.
This is a fairly negligible increase that would not normally influence the ranking of academics to a great extent. Furthermore, stray references especially those with only one or a couple of citations are more likely to be dubious citations (e.g. Google Scholar crawling errors) than master records. Hence, when doing bibliometric research, one could consider simply ignoring stray references when using robust measures such as the h-index or g-index.
Selective merging around the h-index cut-off
There is an alternative strategy that would allow you to minimize the time involved in merging stray references and maximizing the accuracy of the h-index. This involves double-checking for each academic in your sample whether they have any publications that are close to becoming part of the h-index and check whether any stray references can be found for those. An easy way to find duplicates is by sorting the publications by title, publication, author or year. I would normally recommend checking all publications within 5 citations of reaching the required number of citations to be included in the h-index.
Let's work through an example of how this works. The screenshot below shows the publications in my “raw” citation record that might qualify for inclusion in the h-index. The Expatriate Failure article with Christensen is the last paper to be included in the h-index. The next paper [Response styles in cross-national survey research] has 21 citations, but as is immediately apparent, there is a duplicate paper with an equal number of citations. The duplicate paper does not include the subtitle, but a quick verification of the citing articles shows that they are indeed different from those citing the paper with the subtitle. Hence this would be a prime candidate for merging, which increases the h-index to 24.

The next paper [The interaction between language and culture] does have some stray citations (found by sorting the results by publication), but not enough to enter into the h-index. The Publish or Perish program has a fairly high number of stray citations with academics referring to different version, and hence when merged becomes part of the h-index. However, as the original last paper included in only has 24 citations, the h-index still remains at 24. Checking the Expatriate failure paper, however, I find some stray citations for that one too. Merging them into the master record results in a h-index of 25. The Journal quality list also has stray citations, but not enough to bring the total up to 25/26.
However, in this process I also noticed that one my most-cited publications the book Managing the Multinationals actually appears twice, once with a subtitle and 160 citations and once without a subtitle and 37 citations, thus contributing to the h-index twice. Obviously, these two titles need to be merged, bringing us back to an h-index of 24. Although this whole process sounds fairly involved, with a little practice it can actually be done in a couple of minutes, whilst for some author a full merge of stray citations can easily take 15-20 minutes. Hence selective merging might be a good compromise.
This process has also taught us two important generic lessons for selective merging:
- Publications with subtitles can often appear twice, once with and once without the subtitle, so it is worthwhile to check them.
- Your most highly cited publications might appear in the h-index twice as the number of stray citations is large enough to enter as a separate publication.
Age or author corrected metrics
Another decision to make in terms of indices is whether or not to correct for the age of the publications (using measures such as the contemporary h-index, the Age Weighted Citation Rate or the AW-index), and the length of the academic career of the academics under study (using Hirsch's m quotient). A similar decision needs to be made with regard to co-authorships versus single authorships. Publish or Perish offers three variants for an Individual h-index that can be used to correct for co-authorships.
Whether or not you correct for age and number of co-authors depends on both your population (see above) and your research question. If your population is very diverse in terms of career stage and/or the extent of co-authorship correcting for this might be a good idea if you want to create a fair ranking of academics by research impact relative to opportunity.
However, this is dependent on your research question as well. If you want to find out which academics have had the largest overall impact on a field, then correcting by career stage would not be appropriate. However, if you want to identify academics who have written the largest number of recent influential articles (rising stars), the contemporary h-index might be more relevant. Similarly, if your research question relates to which individuals have had the largest impact on the field, rather than which papers or research projects have had the largest impact, metrics correcting for co-authorship might be appropriate.
Just like different research questions might require different research methods, they might also require different research metrics. Hence, as always it is very important to be clear about what your exact research question is, both for the decision on which population to study and for the decision what metrics to use.